
Context as Code: The Missing Layer for AI-Assisted Development
How treating knowledge like infrastructure transformed our AI agent effectiveness

Welcome to my newsletter. This week, I’m sharing something my team and I have been building that I think could change how you work with AI coding assistants. It’s not a new tool—it’s a discipline. And it’s already changed how we ship software.
The Fifth Time My AI Asked the Same Question
Last month, I asked my AI coding assistant to implement validation for a new feature. It gave me a solid implementation. Two days later, I asked it to extend that validation—and it started from scratch, as if our previous conversation never happened.
“What validation patterns are you using?” it asked.
“The ones we discussed Tuesday,” I replied, frustrated.
“I don’t have context about Tuesday’s conversation.”
This wasn’t an AI problem. It was an infrastructure problem.
My team had invested heavily in AI coding assistants. We had the best models, the IDE integrations, the MCP servers connecting to our tools. But every conversation started at zero. Every context window was a blank slate. Our AI was brilliant but amnesiac.
Then we asked ourselves: What if we treated context like code?
The Insight: IaC → CaC
A decade ago, we stopped manually configuring servers. Infrastructure as Code (IaC) changed everything—version-controlled, reviewable, repeatable infrastructure. Terraform, CloudFormation, and Pulumi became standard.
But we never applied this thinking to knowledge.
Our decisions live in Slack threads that disappear. Our architectural context exists in someone’s head. Our “why we did it this way” rationale is tribal knowledge, passed down through pair programming and coffee chats.
AI agents can’t access tribal knowledge. They can’t search your memory. They can only work with what’s written down—and most of what matters isn’t.
Context as Code (CaC) is the answer: treating decisions, plans, designs, and institutional knowledge as versioned, reviewed, and executable artifacts.
What We Built
My team created a dedicated Git repository—not for code, but for context. Here’s what it contains:

The structure isn’t revolutionary. The discipline is.
The Three Pillars of Context as Code
Pillar 1: Context is Iterative, Not Linear
Traditional documentation assumes a waterfall: plan → execute → document. Reality is messier.
I learned that context and code evolve together:
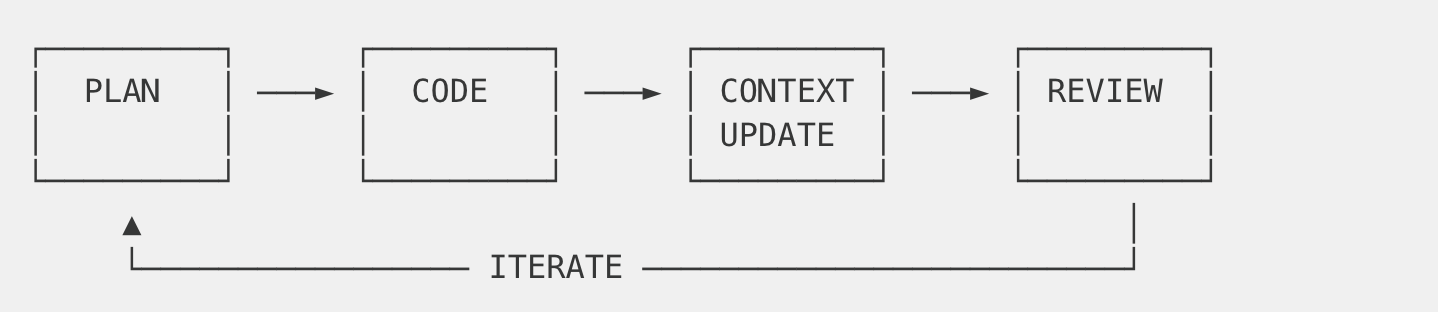
Every coding session generates insights. Those insights update the context. The updated context informs the next session. We commit context changes alongside code changes—same branch name, parallel evolution.
Our commit history tells the story:

Each version represents a cycle where code revealed insight, and insight was captured.
Pillar 2: Git is a Knowledge Management System
Git isn’t just for source code. It’s the best knowledge management system ever built.
Branch — Code: Feature isolation → Context: Task context isolation
Commit — Code: Code checkpoint → Context: Knowledge checkpoint
Merge Request — Code: Code review → Context: Context review
History — Code: Code evolution → Context: Decision evolution
Blame — Code: Who changed this line → Context: Who made this decision
Diff — Code: What code changed → Context: What knowledge changed
We use the same branch naming across code and context repos:

This creates traceability. When someone asks “why did we build it this way?”, the answer is in the same branch name, reviewable in GitLab.
Pillar 3: Multiple Consumers, Single Source
Here’s what surprised us: developers aren’t the only consumers of context.
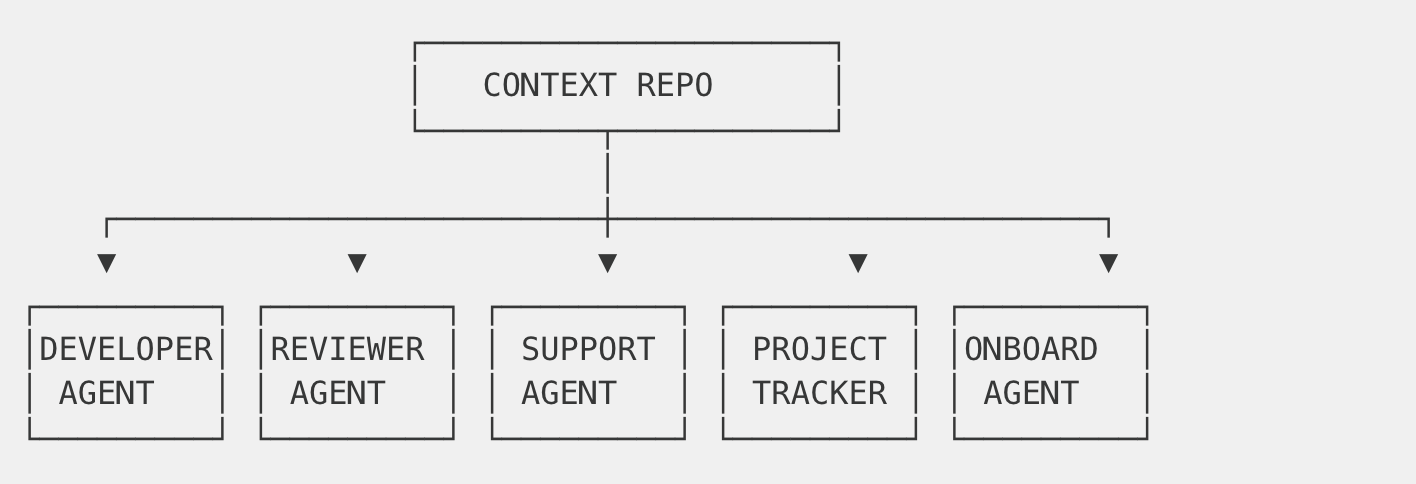
MR Reviewer Agent: Our automated code review bot reads the game plan before reviewing code. It checks: “Does this implementation match the documented design?” It validates against Figma specs via MCP, verifies ticket dependencies from Jira, and ensures test coverage matches requirements.
Support Agent: Customer support chatbots can answer deep technical questions. “Why is the session timeout limited to 30 minutes?” The answer is in our context repo—a product decision documented with rationale.
Project Tracking: Status dashboards auto-populate from context. Each ticket folder has a README with status, and automated tools aggregate it into executive dashboards.
Onboarding Agent: New team members get an AI assistant that actually knows the codebase—not just the code, but the why behind it.
The context repo becomes a knowledge API serving all these consumers.
The MCP Bridge: Connecting Static Context to Live Systems
Static documentation gets stale. This is the oldest complaint about docs. Our answer: MCP servers as intelligent bridges.
When our AI agent needs to answer a question, it doesn’t just read context files. It cross-references with live systems:

The agent combines documented architecture with live production data. It gives answers backed by evidence, not just documentation.
We use several MCP integrations:
Atlassian — Jira ticket status, Confluence specs
Figma — Design specs, component definitions
Datadog — Production logs, metrics, traces
Example 1: Data-Driven Feature Discovery
We needed to design a bulk settings editor. Instead of guessing what users want, we asked the agent to analyze production data:

The feature design document now has production evidence, not assumptions. Product managers can make informed decisions.
Example 2: Design-to-Code Pipeline
When implementing a new UI component, the agent bridges Figma designs with our design system:
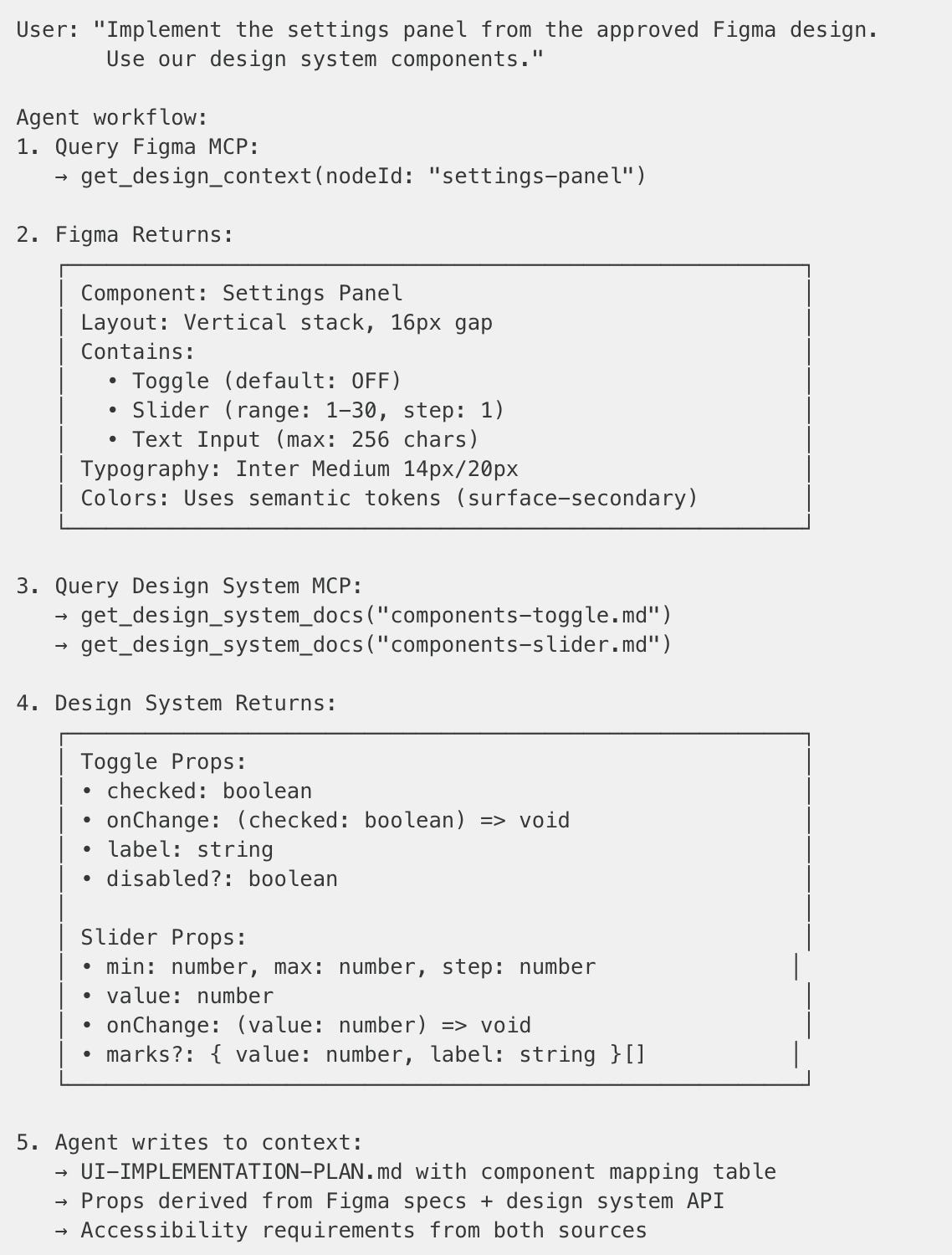
The result: implementation plan that’s aligned with design from the start, not after three rounds of review comments.
Example 3: Cross-System Impact Analysis
When investigating a production issue, the agent synthesizes across systems:

This transforms context from “what we wrote down” to “what we wrote down, verified against production.”
Real Results: A Feature Implementation
Let me show you how this works in practice.
My team was implementing a platform redesign—a complex feature spanning five microservices, three teams, and two months of work.
Before CaC, this would have meant:
Slack threads with key decisions buried in noise
Confluence pages that diverged from implementation
New team members asking the same questions repeatedly
AI assistants starting every conversation from scratch
The Context Pyramid: Layers That Build on Each Other
What made CaC effective wasn’t just having documentation—it was having layered context where each layer builds on the others. Nothing needs to be rewritten or reinvented. Each layer references the knowledge below it.
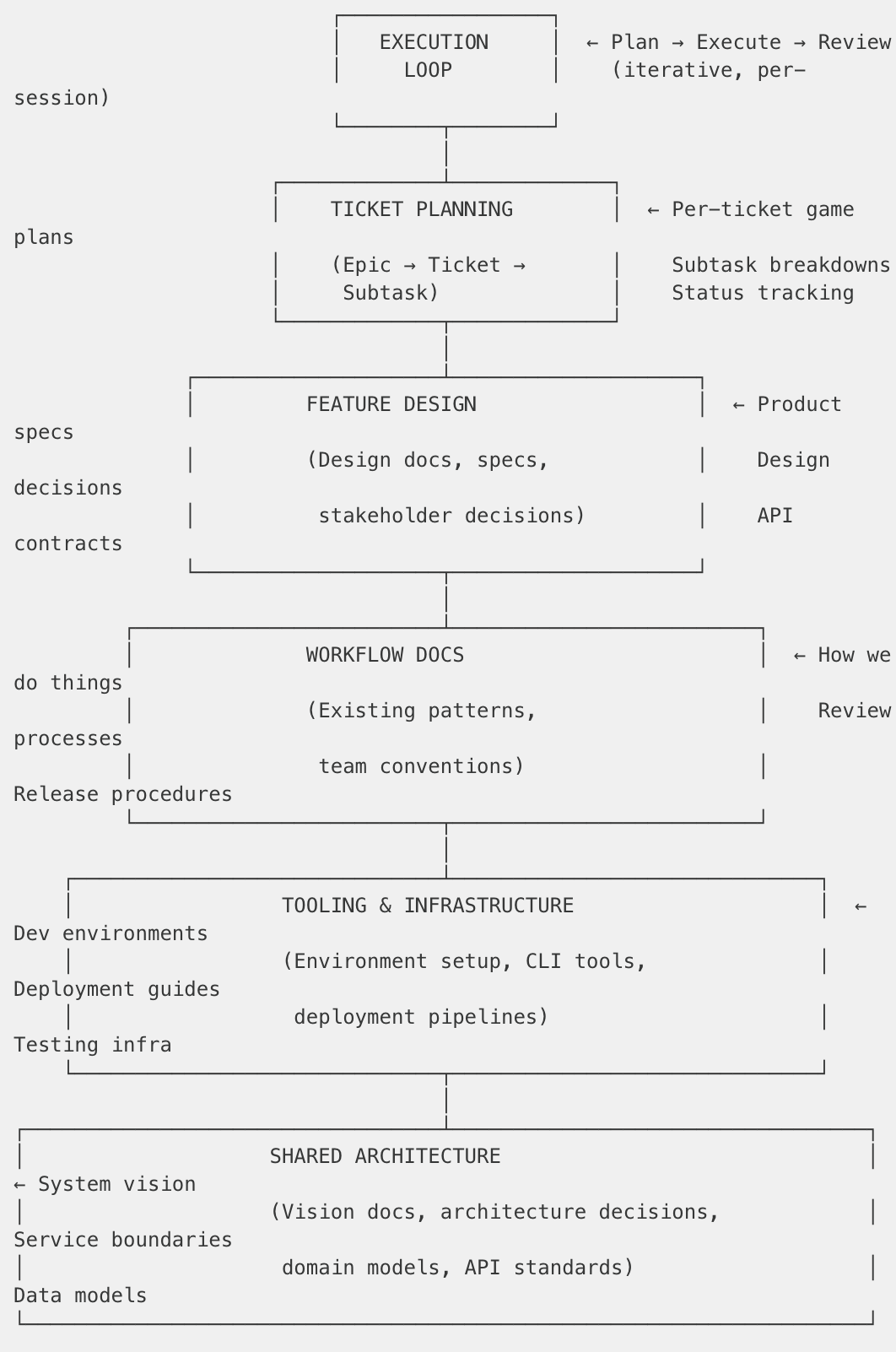
The key insight: It’s an evolving graph, not isolated documents.
When I write a ticket-level game plan, I don’t rewrite the architecture. I reference it:

The AI agent can traverse these references. It doesn’t need me to copy-paste the architecture into every ticket. It follows the graph.
What We Actually Created

But this ticket-level context didn’t exist in isolation. It referenced:
Layer 1: Our shared architecture docs (service boundaries, data models)
Layer 2: Our infrastructure docs (how to spin up test environments)
Layer 3: Our workflow docs (code review checklist, release process)
Layer 4: The feature design docs (product spec, stakeholder decisions)
The UI-IMPLEMENTATION-GAMEPLAN.md became a living document. It started at v1.0 with our initial plan. By the time we merged, it was at v5.1—each version capturing learnings from implementation.
The Execution Loop at the Top
At the pyramid’s peak is the execution loop—the iterative cycle that happens during actual implementation:
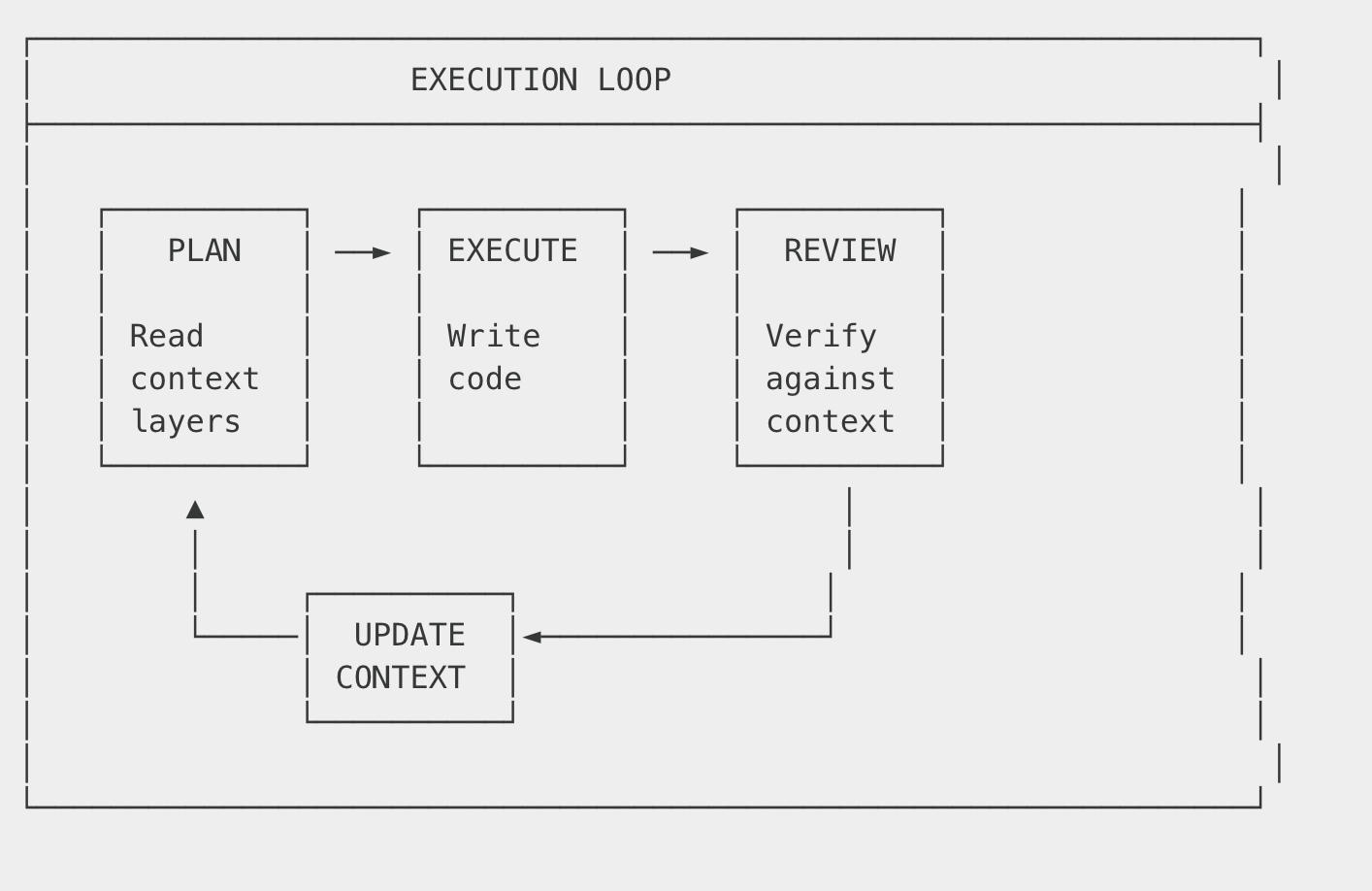
This loop runs continuously. The context pyramid provides the foundation; the execution loop is where work happens.
The Patterns That Emerged
After two months, clear patterns emerged:
Pattern 1: Dual-Audience Documentation
We write for both humans and AI:

Humans skim the overview. AI agents extract the precise specifications.
Pattern 2: Commits as Cross-Repository Metadata
Commits aren’t just version markers—they’re metadata that connects source code and context as they evolve together.

Why this matters:
The reference chain builds sequentially—each commit can only reference what already exists. But over time, this creates full traceability in both directions:
Context comes first, code references it:

When code surfaces learnings, NEW context references that code:

Then new code references the updated context:

Version numbers track evolution.
v1.0→v1.1→v2.0shows the context evolved. Major version = significant design change. Minor = refinements during implementation.Git blame works in both directions. “Why does this code handle timeout=0 specially?” → check the
Context:reference → read the decision. “Who decided timeout=0 means disable?” →git blamethe context → find theRefs:to the code that surfaced it.
The commit message formats:
Source repo (code):

Context repo:

This creates a reference chain that grows over time. Start anywhere, follow the links forward or backward, get the full picture.
Example: A feature evolving through 6 commits

Reading this timeline, you can trace:
Forward: Design (v1.0) → Implementation → Fix discovers edge case → Context updated (v1.1) refs the fix → Review feedback → Context updated (v2.0) → Refactor refs v2.0
Backward: “Why is validation in a separate module?” → refactor refs v2.0 → v2.0 says “MR review” → “What was the edge case?” → v1.1 refs the fix commit → read the fix
The key insight: Each commit only references what already exists. The chain builds sequentially, but over time you get full traceability in both directions.
Pattern 3: Behavior-First Development (TDD Without Writing Tests)
Here’s a shift that surprised me: we do TDD, but we don’t write test code—we write expected behaviors first.
Traditional TDD says: write the test, watch it fail, write code to pass. But the test itself is implementation detail—it’s coupled to a framework, a language, a specific assertion library.
Behavior-First Development inverts this:

Why this works:
Behaviors are stable, implementations change. Your expected behavior (”return 400 for invalid input”) doesn’t care if you use Jest, Pytest, or Go testing. It doesn’t care if the API is REST or GraphQL. The behavior is the contract.
Behaviors validate both context AND code. When the agent builds the implementation plan, it checks: “Does this plan satisfy all behaviors?” When it writes code, it checks again. The behavior doc is your acceptance criteria throughout.
Behaviors are human-readable. Product managers can read and approve behavior specs. They can’t (and shouldn’t) read Jest assertions.
AI agents generate the actual tests. The agent reads the behavior spec and generates tests in whatever framework your codebase uses. The behavior is the context. The test code is implementation detail.
## Edge Cases (added during implementation)
- Given timeout = 0: Treat as "disable timeout"
- Given timeout = null: Use default (30 minutes)
- Given timeout = negative: Return 400, invalid value
When edge cases emerge during implementation, we add them to the behavior doc—not buried in test files. The context grows. The next developer (or AI agent) sees the full picture.
This is TDD’s promise—design through specification—without the coupling to test frameworks. It’s BDD for the AI age.
How to Start
You don’t need to boil the ocean. Start small:
Week 1: Create the Structure
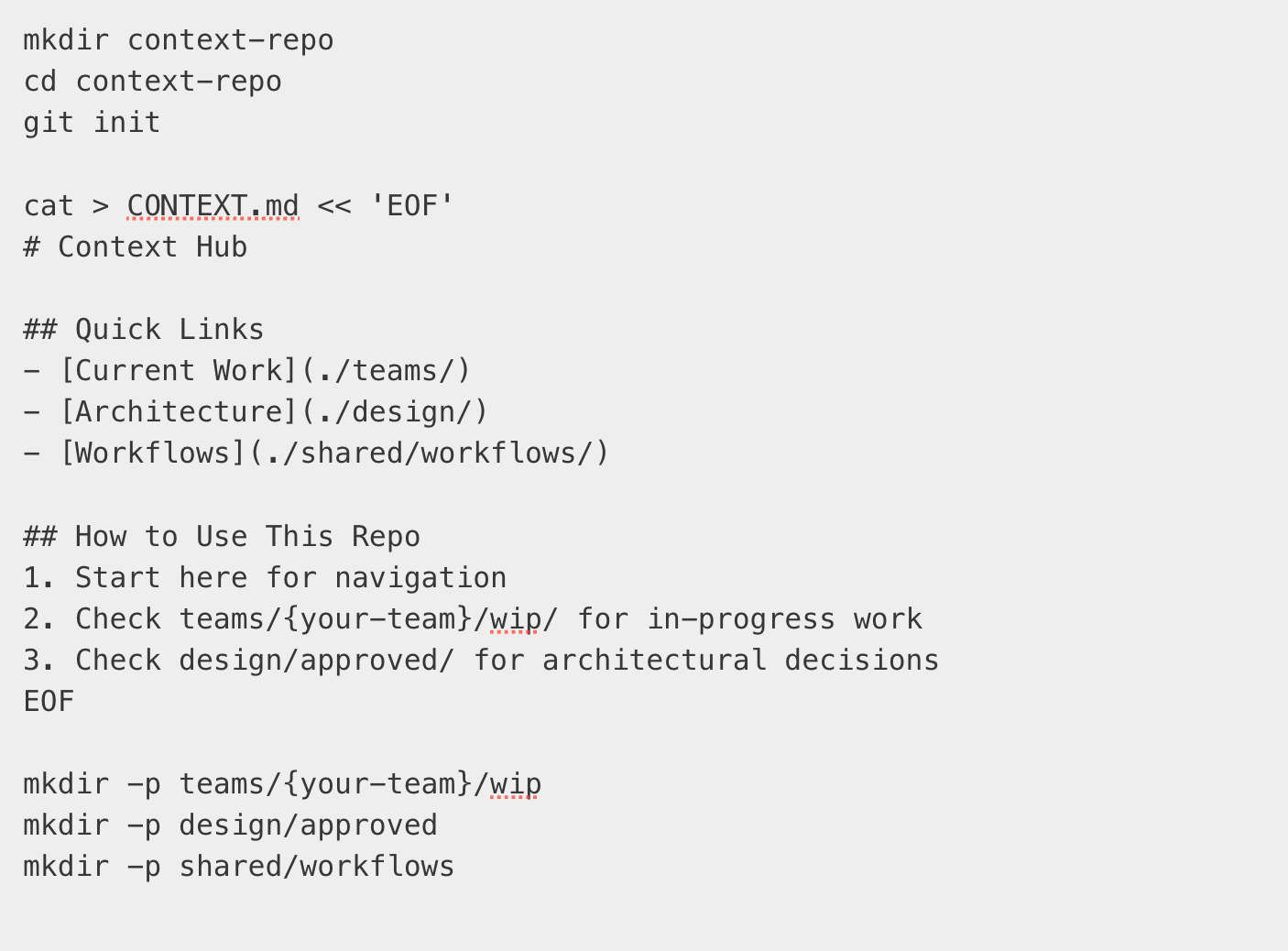
Week 2: Document Your Current Task
Pick one active ticket. Create its context:

Commit after every meaningful decision. Use version numbers.
Week 3: Add IDE Integration
If you use Cursor, create .cursor/rules/:
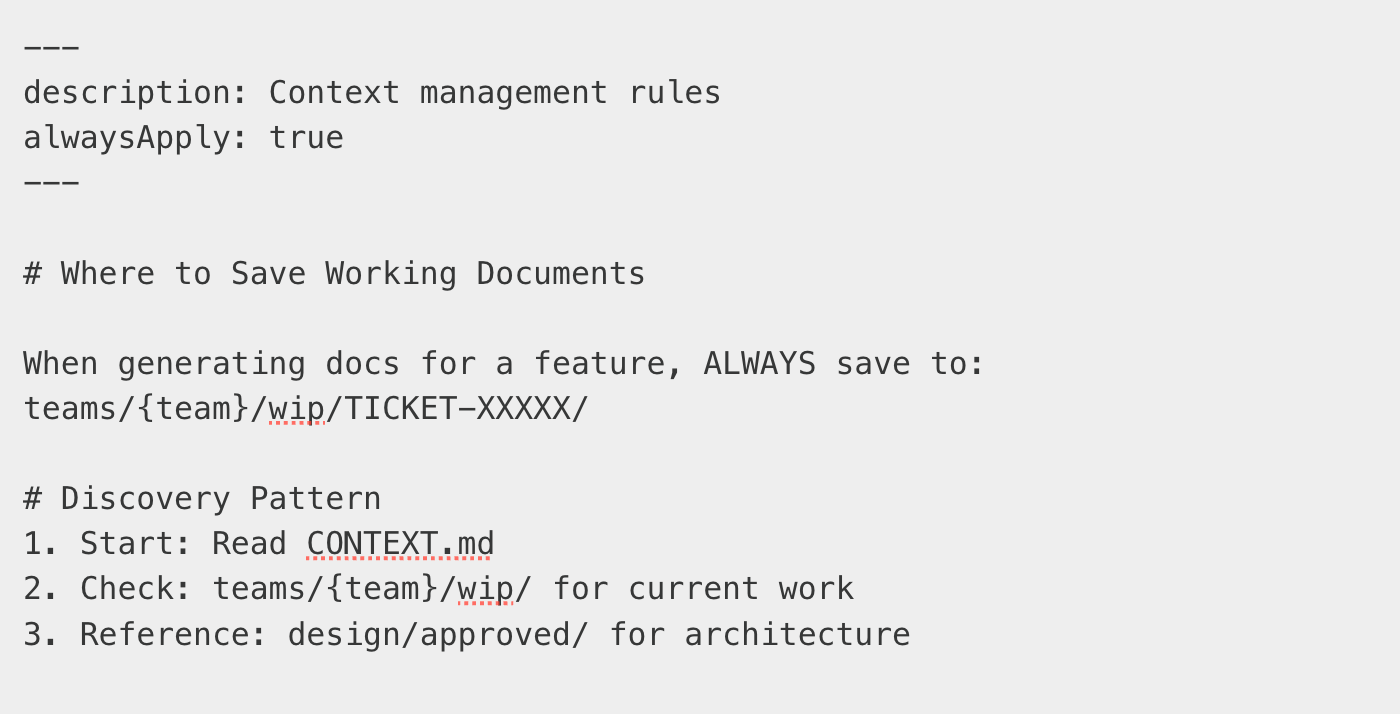
Now your AI assistant knows where to find and save context.
Week 4: Add Your First MCP Query Template
In your monitoring or debugging docs, add MCP query examples:

This turns documentation into runnable playbooks.
Open Questions: What We Haven’t Solved Yet
Two months in, we have more questions than answers. I’m sharing these because I think the community needs to wrestle with them together.
Question 1: What’s the Source of Truth?
If we have both Context as Code and source code, which one wins?

Today, we treat code as the ultimate truth—context documents the intent, code implements the reality. But this feels backwards. Shouldn’t the intent be authoritative?
We don’t have a good answer yet.
Question 2: How Do We Manage Divergence?
Context and code will drift apart. Someone fixes a bug without updating the game plan. Someone changes a validation rule during code review.
Current approach: discipline and code review. But this doesn’t scale.
Possible futures:
CI checks that compare context docs against code behavior
Agents that detect drift and flag inconsistencies
Bi-directional sync where code changes auto-update context
None of these exist yet. We’re managing divergence manually, and it’s fragile.
Question 3: What Should Be the Interface?
When a developer (or agent) needs information, what should they query?
Code — Pros: Always accurate. Cons: No “why”, hard to navigate.
Context — Pros: Human-readable, includes rationale. Cons: Can be stale.
Agent synthesis — Pros: Best of both, always fresh. Cons: Depends on agent quality.
I’m increasingly convinced the answer is agent synthesis—a projection that combines code reality with context intent. The agent becomes the interface, not the files.
But this raises new questions: How do we trust agent synthesis? How do we audit it?
Question 4: Who Manages the Context Repo?
Right now, humans manage the context repository manually via Git. We write the docs. We commit. We review PRs.
But as we add more input streams—

—the volume becomes unmanageable for humans.
The emerging need: An agent that manages the context repo itself. It would:
Watch input streams for relevant information
Auto-update context docs when decisions are made elsewhere
Flag when context diverges from code
Suggest context PRs for human approval
We’re not there yet. But I think this is where CaC inevitably leads: context management as an agent’s job, with humans as approvers, not authors.
The Mindset Shift
CaC isn’t a tool. It’s a discipline.
It requires believing that the “why” is as important as the “what.” That context is not overhead—it’s infrastructure. That your AI assistant’s effectiveness is bounded by the quality of context you provide.
IaC taught us: Don’t configure servers by hand. Codify it.
CaC teaches us: Don’t keep decisions in your head. Codify them.
Your future self will thank you. Your AI assistant will thank you. Your team will thank you.
And maybe, just maybe, you’ll stop answering the same question for the fifth time.
This is Part 1 of the “AI Native Engineering” Series
I’m planning to go deeper on specific aspects of this approach:
Context as Code (this post) — The missing infrastructure layer
Behavior-Driven Development with AI Agents — Writing tests as context, not code
Multi-Root Workspaces — Managing context across many repositories
Subscribe to follow along. I’ll share the exact configurations, templates, and workflows we use—copy-paste ready.
Key Takeaways
Context as Code (CaC) applies IaC principles to knowledge—version-controlled, reviewable, repeatable.
Context is iterative: Plan and code evolve together. Commit context changes alongside code.
Git is a knowledge system: Branches, commits, MRs, and blame work for decisions, not just code.
Multiple consumers: Developers, reviewer agents, support bots, and dashboards all consume the same context.
MCP bridges static and live: Connect documentation to Datadog, Jira, Figma for verified answers.
Start small: One repo, one ticket, one game plan. Build the habit before the infrastructure.
Thanks for reading. If this resonated with you, I’d love to hear about it.
Hit reply and tell me: What’s the biggest context problem you face with AI assistants? I read every response.
Ron Bendet is a Software Engineer becoming an AI Native Engineer—exploring how AI changes the way we build software. You can find him on LinkedIn